I. Introdução
1.1. Conceitos
Um banco de dados, muitas vezes também chamado de base de dados, é um conjunto de arquivos estruturados de forma a facilitar o acesso a conjuntos de dados que descrevem determinadas entidades do mundo. Por exemplo, um banco de dados de funcionários de uma firma contém tipicamente ao menos três arquivos: dados pessoais (nome, endereço, dados de cocumentos), dados funcionais (cargo, data de admissão, etc) e dados para pagamento (salário base, faixas, etc).
A medida que o volume e os tipos de dados armazenados aumentam, é preciso utilizar softwares especiais para gerenciar os dados, os chamados SGBDs (Sistemas de Gerenciamento de Banco de Dados). Um SGBD é um software de caráter geral para a manipulação eficiente de grandes coleções de informações estruturadas e armazenadas de uma forma consistente e integrada. Tais sistemas incluem módulos para consulta, atualização e as interfaces entre o sistema e o usuário.
SGBD è Coleção de dados inter-relacionados + Conjunto de programas para acessá-los;
1.2. Objetivos
v Disponibilizar dados integrados para uma grande variedade de usuários e aplicações através de interfaces amigáveis;
v Garantir a Privacidade dos dados através de medidas de segurança dentro do sistema (como visões, permissões, senhas de acesso);
v Permitir compartilhamento dos dados de forma organizada, mediando a comunicação entre aplicações e banco de dados e administrando acessos concorrentes;
v Possibilitar independência dos dados, poupando ao usuário a necessidade de conhecer detalhes de implementação interna, organização de arquivos e estruturas de armazenamento.
1.3. SGBD x Sistemas de Arquivos
Sistemas de processamento de arquivos caracterizam-se por uma série de registros guardados em diversos arquivos e uma série de programas aplicativos para extrair e adicionar registros nos arquivos apropriados.
ü Desvantagens deste sistema (arquivos)
v Redundância e inconsistência de dados;
v Dificuldade no acesso aos dados;
v Isolamento de dados;
v Problemas de atomicidade;
v Anomalias de acesso concorrente;
v Problemas de segurança;
v Problemas de integridade;
1.4. Arquiteturas de Sistemas de Banco de Dados
A arquitetura de um sistema de banco de dados está fortemente relacionada com as características do sistema operacional sobre o qual o SGBD estará rodando.
Sistemas Centralizados
Sistemas centralizados são aqueles executados sobre um único sistema operacional, não interagindo com outros sistemas. Tais sistemas podem ter a envergadura de um sistema de banco de dados de um só usuário executado em um computador pessoal ou em sistemas de alto desempenho, denominados de grande porte.
Sistema Cliente-Servidor
Como os computadores pessoais tem se tornado mais rápidos, mais poderosos e baratos, há uma tendência de seu uso nos sistemas centralizados. Terminais conectados a sistemas centralizados estão sendo substituídos por computadores pessoais.
Como resultado, sistemas centralizados atualmente agem como sistemas servidores que atendem a solicitações de sistemas clientes.
As funcionalidades de um banco de dados podem ser superficialmente divididas em duas categorias – front-end e back-end . O back-end gerencia as estruturas de acesso, desenvolvimento e otimização de consultas, controle de concorrência e recuperação. O front-end consiste em ferramentas como formulários, gerador de relatórios e recursos de interface gráfica. A interface entre o front-end e o back-end é feita através de SQL ou de um programa de aplicação.
Sistemas Paralelos
Sistemas paralelos imprimem velocidade ao processamento e à CPU por meio do uso em paralelo de CPU’s e discos.
No processamento paralelo, muitas operações são realizadas ao mesmo tempo, ao contrário do processamento serial, no qual os passos do processamento são sucessivos. Um equipamento paralelo de granulação-grossa consiste em poucos e poderosos processadores (maioria dos servidores atuais) enquanto que um paralelismo intensivo ou de granulação fina usa milhares de pequenos processadores. Computadores paralelos com centenas de processadores já estão disponíveis comercialmente.
As duas principais formas de avaliar o desempenho de um sistema de banco de dados são através do throughput e tempo de resposta. A primeira diz respeito ao número de tarefas que podem ser executadas em um dado intervalo de tempo. Um sistema que processa um grande número de pequenas transações pode aumentar o throughput por meio do processamento de diversas transações em paralelo. O tempo de resposta diz respeito ao tempo total que o sistema pode levar para executar uma única tarefa. Um sistema que processa um grande número de pequenas transações pode aumentar o throughput por meio do processamento de diversas transações em paralelo. Um sistema que processa um grande volume de transações pode reduzir o tempo de resposta por meio de processamento em paralelo.
Sistemas distribuídos
Em um sistema distribuido o banco de dados é armazenado em diversos computadores. Os computadores de um sistema de banco de dados distribuídos comunicam-se com outros por intermédio de vários meios de comunicações, como redes de alta velocidade ou linhas telefônicas.
As principais diferenças entre os banco de dados paralelos sem compartilhamento e os bancos de dados distribuídos são que, nos bancos de dados distribuídos, há a distribuição física geográfica, administração separada e uma intercomunicação menor. Outra importante diferença é que, nos sistemas distribuídos, distinguimos transações locais (acessa um único computador) de globais (envolve mais de um computador).
Há diversas razões para a utilização de sistemas de banco de dados distribuídos, dentre as quais podemos citar: Compartilhamento dos dados (usuários de um local podem ter acesso a dados residentes em outros – Ex. Bancos), autonomia (Cada local administra seus próprios dados) e disponibilidade (Se porventura uma SGBD sai do ar, os demais podem continuar em operação). por um outro lado, existem algumas desvantagens relacionadas ao seu uso, dentre as quais podemos citar: Custo de desenvolvimento de software, maior possibilidades de bugs e aumento do processamento e overhead.
1.5. Abstração De Dados
Os SGBD’s provêem aos usuários uma visão abstrada dos dados. I. E., os usuários não precisam saber como os dados são armazenados e mantidos.
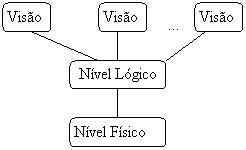
Níveis de abstração de dados:
v Visual: Diz respeito a forma como os Dados são vistos pelos usuários (individualmente). Um determinado usuário, tanto pode ser um programador de aplicações, como um usuário final. O DBA é um caso especial importante. Ao contrário dos usuários comuns, o DBA terá de se interessar pelos níveis conceitual e físico também.
v Lógico : É a visão global do grupo de usuários. A visão lógica é a representação de todo o conteúdo de informações do banco de dados, também um tanto abstrato quando comparada à forma como os dados são fisicamente armazenados, que também pode ser bem diferente da maneira como os dados são vistos por qualquer usuário em particular. A grosso modo, podemos dizer que a visão lógica é a visão dos dados “como realmente são”, e não como os usuários são forçados a vê-los devido às restrições de linguagem ou hardware.
v Físico: Diz respeito a forma como os dados estão armazenados fisicamente.
1.6. Modelos de banco de dados
Sistemas Relacionais
|
Nome |
Rua |
Cidade |
Número_Conta |
|
Ana |
Maria José |
Vitória |
900 |
|
Maria |
João da Cruz |
Vitória |
556 |
|
Maria |
João da Cruz |
Vitória |
647 |
|
José |
Henrique Rosetti |
Vitória |
801 |
|
José |
Henrique Rosetti |
Vitória |
647 |
Figura 1.1: A relação Cliente
|
Nome_ Agência |
número |
Saldo |
|
Centro |
900 |
62 |
|
Praia do Canto |
556 |
6589 |
|
Bento Ferreira |
647 |
3245 |
|
Jucutuquara |
801 |
2258 |
Figura 1.2: A relação Conta
Sistemas Hierárquicos
Um banco de dados hierárquico compõe-se de um conjunto ordenado de árvores, mais precisamente, de um conjunto ordenado de ocorrências múltiplas de um tipo único de árvore.
O tipo árvore compõe-se de um único tipo de registro “raiz”, juntamente com um conjunto ordenado de zero ou mais (nível inferior) tipos de subárvores dependentes. Um tipo de subárvore, por sua vez, também se compõe de um único tipo de registro. A associação entre tipos de registros segue uma hierarquia estabelecida através de diversos níveis . No primeiro nível, ou superior, situa-se o tipo de registro “Raiz” . Subordinado a ele, em nível 2, uma série de outros tipos de registros em nível 2. A cada tipo de registro em nível 2 subordina-se um outro conjunto de tipos de registros. A própria estrutura hierárquica define as suas rotas de acesso, facilitando, portanto, a manutenção do banco de dados.
É importante notar que um determinado tipo de registro A, num determinado nível K, possui ligação com um e somente um tipo de registro B, de nível K-1 (superior). Nestas condições A é dito registro PAI de B, que por sua vez é registro FILHO de A . No entanto, um tipo de registro A pode estar ligado a diversos filhos ao nível de B. Todas as ocorrências de um dado tipo de filho que compartilham uma ocorrência de pai comum são chamadas de Gêmeas.

Figura 1.3: Exemplo de “Modelo Hierárquico”.
Manipulação de dados hierárquicos
A linguagem de manipulação de dados hierárquicos compõe-se de um conjunto de operadores para o processamento de dados representados sob a forma de árvore.
Exemplo:
1) Operador para localizar uma árvore específica no banco de dados;
2) Operador para passar dessa árvore para a próxima;
3) Operadores para passar, de registro a registro, dentro da árvore, para cima e para baixo nos diversos percursos hierárquicos;
4) Operadores para passar de registro a registro, de acordo com a seqüência hierárquica do banco de dados;
5) Operador para inserir um novo registro em uma posição específica dentro de tal árvore;
6) Operador para eliminar um registro específico.
Sistemas Rede
Um banco de dados em rede consiste em uma coleção de registros que são concatenados uns aos outros por meio de ligações. Um registro é em muitos aspectos similar a uma entidade no modelo entidade-relacionamento. Uma ligação é uma associação entre precisamente dois registros. Assim, uma ligação pode ser vista como uma forma restrita (binária) de relacionamento no modelo ER.
Tanto o Modelo Rede como o Modelo Hierárquico podem ser considerados como estruturas de dados a nível lógico mais próximo do nível físico. Devido a esta proximidade ao nível físico, as estruturas de dados rede e hierárquica exibem as rotas lógicas de acesso de dados de forma acentuada, possibilitando a localização lógica de um determinado registro no banco de dados.
O Modelo Relacional, quando comparado com a Estrutura Rede e Hierárquica é mais orientado para modelagem do que como modelo com rotas de acesso, muito embora, podemos considerar as diversas redundâncias existentes em diversas tabelas como sendo uma forma de rota de acesso.
O Modelo Rede utiliza como elemento básico de dados a ocorrência de registro. Um conjunto de ocorrência de registro de um mesmo tipo determina um tipo de registro.
Um conjunto de tipos de registros relacionados entre si, através de referências especiais, forma uma estrutura de dados em rede. As referências especiais são conhecidas como LINKS (ligações), que por sua vez podem ser implementadas sob a forma de ponteiros.
As referências estão normalmente inseridas junto com as ocorrências de registro; assim, todo o acesso a um próximo registro utiliza o ponteiro inserido no registro corrente disponível.

Figura 1.4: Exemplo de “Modelo Rede”
1.7. Instâncias e Esquemas
Um banco de dados muda ao longo do tempo por meio das informações que nele são inseridas ou excluídas. O conjunto de informações contidas em determinado banco de dados, em um dado momento, é chamado instância do banco de dados. O projeto geral do banco de dados é chamado esquema.
1.8. Independência De Dados
Pode ser definida como a “Imunidade das aplicações à estrutura de armazenamento e à estratégia de acesso”, ou seja, diminuir as alterações de programas devido a modificações nos dados do banco de dados.
As modificações nos dados não se referem às atualizações temporais dos valores dos itens de dados e sim quanto ao tamanho, formato, precisão, índices, etc... , de itens de dados.
Existem dois níveis de Independência de Dados:
a) Independência Física de dados: É a habilidade de modificar o esquema físico sem a necessidade de reescrever os programas aplicativos. As modificações no nível físico são ocasionalmente necessárias para melhorar o desempenho.
b) Independência Lógica de dados: É a habilidade de modificar o esquema conceitual sem a necessidade de reescrever os programas aplicativos. As modificações no nível conceitual são necessárias quando a estrutura lógica do banco de dados é alterada.
Qual abordagem é mais fácil de ser alcançada?
1.9. Tarefas de um SGBD
v Interação com o gerenciador de arquivos;
v Cumprimento da integridade;
v Cumprimento da segurança;
v Cópias de segurança e recuperação;
v Controle de concorrência.
1.10. Tarefas de um Administrador de Banco de Dados (DBA)
O Administrador do Banco de Dados (DBA) é a pessoa (ou grupo de pessoas) responsável pelo controle do banco de dados.
Dentre essas funções citamos:
a) Decidir o conteúdo de informações do banco de dados: Deve identificar as entidades de interesse da empresa e a informação a registrar em relação a essas entidades. A partir dai, o DBA poderá definir o conteúdo do banco de dados, descrevendo um esquema conceitual.
b) Decidir a Estrutura de Armazenamento e a Estratégia de Acesso: Estruturas apropriadas de armazenamento e métodos de acesso são criadas escrevendo-se um conjunto de definições que são traduzidas pelo compilador de estruturas de dados e de linguagem de definição (DDL).
c) Servir de elo de ligação com usuários: A fim de garantir a disponibilidade dos dados de que estes necessitam.
d) Definir os controles de segurança e integridade: Pode ser considerado parte do esquema conceitual. A DDL conceitual incluirá os recursos para a especificação de tais controles.
f) Definir a estratégia de reserva e recuperação: É de suma importância, na eventualidade de danos à parte do banco de dados causados por erro humano ou por falha de hardware, fazer retornar os dados envolvidos com um mínimo de demora e com as menores conseqüências ao restante do sistema. O DBA deve definir e implementar uma estratégia de recuperação apropriada envolvendo, por exemplo, o descarregamento periódico do banco de dados na memória auxiliar de armazenamento e procedimentos para recarregá-lo, quando necessário.
g) Monitorar o desempenho e atender as necessidades de modificações: O DBA deve organizar o sistema de tal maneira que obtenha “o melhor desempenho para a empresa”; e efetuar os ajustes adequados quanto às necessidades de modificações.
1.11. Estrutura geral do sistema
O sistema de banco de dados está dividido em módulos específicos, de modo a atender a todas as suas funções, onde algumas delas são fornecidas pelo sistema operacional.
Os componentes de processamentos de consultas incluem:
v Compilador DML: traduz comandos DML da linguagem de consulta em instruções de baixo nível, inteligíveis ao componente de execução de consultas;
v Pré-compilador para comandos DML: inseridos em programas de aplicação, que convertem comandos DML em chamadas de procedimentos normais da linguagem hospedeira.
v Interpretador DDL: interpreta os comandos DDL e registra-os em um conjunto de tabelas que contêm metadados, “dados sobre dados”;
v Componentes para o tratamento de consultas: executam instruções de baixo nível geradas pelo compilador DML.
Os componentes para administração do armazenamento de dados incluem:
v Gerenciamento de autorizações e integridade: testam o cumprimento das regras de integridade e a permissão ao usuário no acesso aos dados;
v Gerenciamento de transações: garante que o banco de dados permanecerá em estado consistente a despeito de falhas no sistema e que as transações concorrentes serão executadas sem conflitos em seus procedimentos;
v Administração de arquivos: gerencia a alocação de espaço no armazenamento em disco e as estruturas de dados usadas para representar estas informações armazenadas em disco;
v Administração do buffer: intermediar os dados entre o disco e a memória principal e decide quais dados colocar em cache;
Diversas estruturas de dados são requeridas como parte da implementação do sistema físico, incluído:
a) Arquivo de Dados: Armazena o banco de dados.
b) Dicionário de Dados: Armazena informações sobre os dados do banco de dados;
c) Índices: Permite o acesso mais rápido aos dados.
d) Estatísticas: Armazenam informações sobre o banco de dados e é usado pelo seletor de estratégias.
1.11.1. Linguagem de Definição de Dados (DDL)
Contém a especificação dos esquemas de banco. O resultado da compilação dos parâmetros DDLs é armazenado em um conjunto de tabelas que constituem um arquivo especial chamado dicionário de dados. Um dicionário de dados é um arquivo de metadados.
1.11.2. Linguagem de Manipulação de Dados (DML)
A linguagem de manipulação de dados (DML) é a linguagem que viabiliza o acesso ou a manipulação dos dados de forma compatível ao modelo de dados apropriado.
São responsáveis pela:
v Recuperação da informação armazenada no banco de dados;
v Inserção de novos dados nos bancos de dados;
v Eliminação de dados nos bancos de dados;
v Modificação de dados armazenados no banco de dados;
Dividem-se basicamente em dois tipos:
DMLs Procedurais: exigem que o usuário especifique quais dados são necessários, e como obtê-los;
DMLs Não Procedurais: exige que o usuário especifique quais dados são necessários, sem especificar como obtê-los.
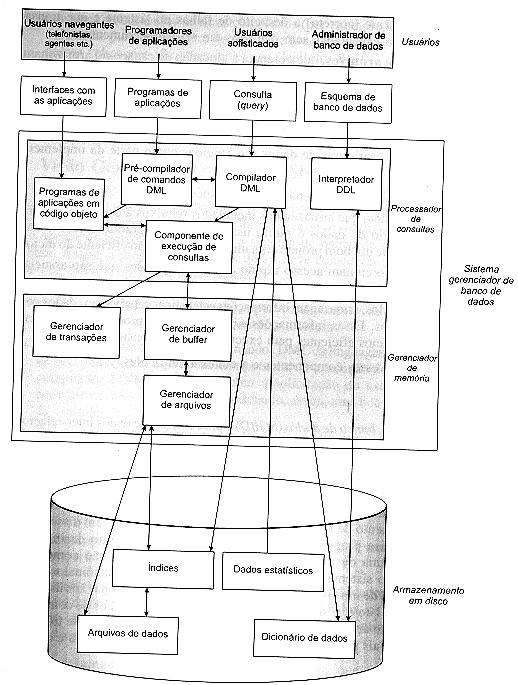
Figura 1.5: Estrutura de um Sistema de Banco de Dados.
